实时计算、离线计算
实时数据、离线数据
可以写一个脚本动态生成提交命令并执行
多表联查产生笛卡尔积,使得中间表数据量爆炸
Resilient Distributed Dataset,RDD
RDD支持transformation和action两种操作,transformation为延迟操作,action为及时操作,transformation会在action执行时进行计算,默认情况下,transformation在每次action执行时都会重新计算,可以设置持久化到内存或者磁盘加速计算
transformaton: map
action: reduce
共享变量
累加器,accumulator
广播变量,broadcast variable
多次任务同名模块测试
spark-submit --master spark://zhengdawei-17000:7077 \
--jars /home/ubuntu/spark-3.4.0/jars/mysql-connector-j-8.0.32.jar \
--conf spark.pyspark.driver.python=/home/ubuntu/virtualenv/tianfu3k/bin/python3 \
--py-files /home/ubuntu/code/backend/projects/data_spark/gsdbsite/scripts/conf.py \
/home/ubuntu/code/backend/projects/data_spark/gsdbsite/scripts/p.py
# 没问题
配置在spark-env或者
export PYSPARK_PYTHON=/home/ubuntu/virtualenv/tianfu3k/bin/python
export PYSPARK_DRIVER_PYTHON=/home/ubuntu/virtualenv/tianfu3k/bin/python
spark.pyspark.python /home/ubuntu/virtualenv/tianfu3k/bin/python
spark.pyspark.driver.python /home/ubuntu/virtualenv/tianfu3k/bin/python
Spark 2.20 以后 SparkSession 合并了 SQLContext 和 HiveContext
df_customers.getNumPartitions()
df_customers.cache() # 以列式存储在内存中
df_customers.persist() # 缓存到内存中
df_customers.unpersist() # 移除所有的blocks
df_customers.coalesce(numPartitions= 1) #返回一个有着numPartition的DataFrame
df_customers.repartition(10) ##repartitonByRange
df_customers.rdd.getNumPartitions()# 查看partitons个数
df_customers.columns # 查看列名
['cID', 'name', 'age', 'gender']
df_customers.dtypes # 返回列的数据类型
df_customers.explain() #返回物理计划,调试时应用
spark-submit --master spark://zhengdawei-17000:7077 \
--driver-class-path /home/ubuntu/spark-3.4.0/jars/mysql-connector-j-8.0.32.jar \
--archives /home/ubuntu/base_data.zip#base_data,/home/ubuntu/code/backend/projects/data_spark/gsdbsite/services.json \
--conf spark.pyspark.driver.python=/home/ubuntu/virtualenv/tianfu3k/bin/python3 \
--py-files /home/ubuntu/gsdbsite0.zip \
--verbose \
/home/ubuntu/code/backend/projects/data_spark/gsdbsite/scripts/calc_pvn_from_pp_to_mongo.py
spark-submit --master spark://zhengdawei-17000:7077 \
--driver-class-path /home/ubuntu/spark-3.4.0/jars/mysql-connector-j-8.0.32.jar \
--archives /home/ubuntu/gsdbsite0.zip#,/home/ubuntu/code/backend/projects/data_spark/gsdbsite/services.json \
--conf spark.pyspark.driver.python=/home/ubuntu/virtualenv/tianfu3k/bin/python3 \
--py-files /home/ubuntu/gsdbsite0.zip \
--verbose \
/home/ubuntu/code/backend/projects/data_spark/gsdbsite/scripts/calc_pvn_from_pp_to_mongo.py
问题
spark-submit --master spark://zhengdawei-17000:7077 \
--driver-class-path /home/ubuntu/spark-3.4.0/jars/mysql-connector-j-8.0.32.jar \
--archives /home/ubuntu/code/backend/projects/data_spark/gsdbsite/services.json,/home/ubuntu/gsdbsite0.zip# \
--conf spark.pyspark.driver.python=/home/ubuntu/virtualenv/tianfu3k/bin/python3 \
--verbose \
/home/ubuntu/code/backend/projects/data_spark/gsdbsite/scripts/calc_rr_pp_with_dependence.py
列操作
Column.alias(*alias, **kwargs) # 重命名列名
Column.asc() # 按照列进行升序排序
Column.desc() # 按照列进行降序排序
Column.astype(dataType) # 类型转换
Column.cast(dataType) # 强制转换类型
Column.between(lowerBound, upperBound) # 返回布尔值,是否在指定区间范围内
Column.contains(other) # 是否包含某个关键词
Column.endswith(other) # 以什么结束的值,如 df.filter(df.name.endswith('ice')).collect()
Column.isNotNull() # 筛选非空的行
Column.isNull()
Column.isin(*cols) # 返回包含某些值的行 df[df.name.isin("Bob", "Mike")].collect()
Column.like(other) # 返回含有关键词的行
Column.when(condition, value) # 给True的赋值
Column.otherwise(value) # 与when搭配使用,df.select(df.name, F.when(df.age > 3, 1).otherwise(0)).show()
Column.rlike(other) # 可以使用正则的匹配 df.filter(df.name.rlike('ice$')).collect()
Column.startswith(other) # df.filter(df.name.startswith('Al')).collect()
Column.substr(startPos, length) # df.select(df.name.substr(1, 3).alias("col")).collect()
spark-shell
spark-submit
spark-class
两个问题
zip包的结构层次决定了导包能否成功
切换工作目录解决了配置文件问题
但是有覆盖风险
调优
广播大变量减少网络传输
如果我们有一个数据集很大,并且在后续的算子执行中会被反复调用,那么就建议直接把它广播(broadcast)一下。当变量被广播后,会保证每个executor的内存中只会保留一份副本,同个executor内的task都可以共享这个副本数据。如果没有广播,常规过程就是把大变量进行网络传输到每一个相关task中去,这样子做,一来频繁的网络数据传输,效率极其低下;二来executor下的task不断存储同一份大数据,很有可能就造成了内存溢出或者频繁GC,效率也是极其低下的。
持久化减少中间计算
数据倾斜
在Spark中比较容易出现倾斜的操作,主要集中在distinct、groupByKey、reduceByKey、aggregateByKey、join、repartition等,可以优先看这些操作的前后代码。而为什么使用了这些操作就容易导致数据倾斜呢?大多数情况就是进行操作的key分布不均,然后使得大量的数据集中在同一个处理节点上,从而发生了数据倾斜。
大概的思路就是对一些大量出现的key,人工打散,从而可以利用多个task来增加任务并行度,以达到效率提升的目的,下面是代码demo,分别从RDD 和 SparkSQL来实现。
分配随机数再聚合
# Way1: PySpark RDD实现
import pyspark
from pyspark import SparkContext, SparkConf, HiveContext
from random import randint
import pandas as pd
# SparkSQL的许多功能封装在SparkSession的方法接口中, SparkContext则不行的。
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("sam_SamShare") \
.config("master", "local[4]") \
.enableHiveSupport() \
.getOrCreate()
conf = SparkConf().setAppName("test_SamShare").setMaster("local[4]")
sc = SparkContext(conf=conf)
hc = HiveContext(sc)
# 分配随机数再聚合
rdd1 = sc.parallelize([('sam', 1), ('sam', 1), ('sam', 1), ('sam', 1), ('sam', 1), ('sam', 1)])
# 给key分配随机数后缀
rdd2 = rdd1.map(lambda x: (x[0] + "_" + str(randint(1,5)), x[1]))
print(rdd.take(10))
# [('sam_5', 1), ('sam_5', 1), ('sam_3', 1), ('sam_5', 1), ('sam_5', 1), ('sam_3', 1)]
# 局部聚合
rdd3 = rdd2.reduceByKey(lambda x,y : (x+y))
print(rdd3.take(10))
# [('sam_5', 4), ('sam_3', 2)]
# 去除后缀
rdd4 = rdd3.map(lambda x: (x[0][:-2], x[1]))
print(rdd4.take(10))
# [('sam', 4), ('sam', 2)]
# 全局聚合
rdd5 = rdd4.reduceByKey(lambda x,y : (x+y))
print(rdd5.take(10))
# [('sam', 6)]
# Way2: PySpark SparkSQL实现
df = pd.DataFrame(5*[['Sam', 1],['Flora', 1]],
columns=['name', 'nums'])
Spark_df = spark.createDataFrame(df)
print(Spark_df.show(10))
Spark_df.createOrReplaceTempView("tmp_table") # 注册为视图供SparkSQl使用
sql = """
with t1 as (
select concat(name,"_",int(10*rand())) as new_name, name, nums
from tmp_table
),
t2 as (
select new_name, sum(nums) as n
from t1
group by new_name
),
t3 as (
select substr(new_name,0,length(new_name) -2) as name, sum(n) as nums_sum
from t2
group by substr(new_name,0,length(new_name) -2)
)
select *
from t3
"""
tt = hc.sql(sql).toPandas()
tt

RDD
算子(operator)
standalone
- Standalone模式运行机制
- Standalone 集群有 2 个重要组成部分,分别是:
\1. Master(RM):是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责, 一个是用自己的内存存储 RDD 的某个或某些 partition,另一个是启动其他进程和线程(Executor),对 RDD 上的 partition 进行并行的处理和计算。
根据 driver的位置不同, 也分 2 种:
Standalone-Cluster模式
在Standalone Cluster模式下,任务提交后,Master会找到一个 Worker 启动Driver。
Driver启动后向Master注册应用程序,Master根据 submit 脚本的资源需求找到内部资源至少可以启动一个Executor 的所有Worker,然后在这些 Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的 Executor 注册完成后,Driver 开始执行main函数,之后执行到Action算子时,开始划分 tage,每个 Stage 生成对应的taskSet,之后将 Task 分发到各个 Executor 上执行。

Standalone-Client模式
在 Standalone Client 模式下,Driver 在任务提交的本地机器上运行。
Driver启动后向 Master 注册应用程序,Master 根据 submit 脚本的资源需求找到内部资源至少可以启动一个Executor 的所有 Worker,然后在这些 Worker 之间分配 Executor,Worker 上的 Executor 启动后会向Driver反向注册,所有的Executor注册完成后,Driver 开始执行main函数,之后执行到Action算子时,开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。
Application Job Stage Task
Application
Spark应用,一次提交即为一次应用的执行
Job
Job = n * transformation + action ,n为自然数
Stage
Stage 是 Job 的子集,以 RDD 宽依赖(即 Shuffle )为界,遇到 Shuffle 做一次划分
Task
Task 是 Stage 的子集,以并行度(分区数)来衡量,这个 Stage 分区数是多少,则这个Stage 就有多少个 Task
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化的(Time Variant)数据集合,用于支持管理决策和信息的全局共享。其主要功能是将组织透过资讯系统之联机事务处理(OLTP)经年累月所累积的大量资料,透过数据仓库理论所特有的资料储存架构,作一有系统的分析整理,以利各种分析方法如联机分析处理(OLAP)、数据挖掘(Data Mining)之进行,并进而支持如决策支持系统(DSS)、主管资讯系统(EIS)之创建,帮助决策者能快速有效的自大量资料中,分析出有价值的资讯,以利决策拟定及快速回应外在环境变动,帮助建构商业智能(BI)。 所谓主题:是指用户使用数据仓库进行决策时所关心的重点方面,如:收入、客户、销售渠道等;所谓面向主题,是指数据仓库内的信息是按主题进行组织的,而不是像业务支撑系统那样是按照业务功能进行组织的。所谓集成:是指数据仓库中的信息不是从各个业务系统中简单抽取出来的,而是经过一系列加工、整理和汇总的过程,因此数据仓库中的信息是关于整个企业的一致的全局信息。所谓随时间变化:是指数据仓库内的信息并不只是反映企业当前的状态,而是记录了从过去某一时点到当前各个阶段的信息。通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。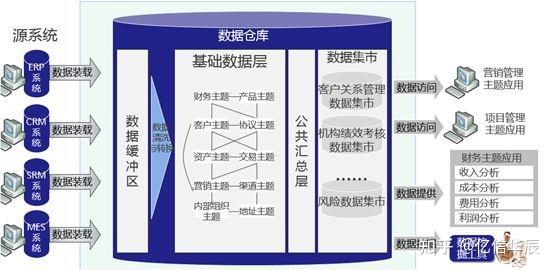
数据湖(Data Lake)是一个存储企业的各种各样原始数据的大型仓库,其中的数据可供存取、处理、分析及传输。数据湖是以其自然格式存储的数据的系统或存储库,通常是对象blob或文件。数据湖通常是企业所有数据的单一存储,包括源系统数据的原始副本,以及用于报告、可视化、分析和机器学习等任务的转换数据。数据湖可以包括来自关系数据库(行和列)的结构化数据,半结构化数据(CSV,日志,XML,JSON),非结构化数据(电子邮件,文档,PDF)和二进制数据(图像,音频,视频)。来源:维基百科。目前,Hadoop是最常用的部署数据湖的技术,所以很多人会觉得数据湖就是Hadoop集群。但其实数据湖是一个概念,而Hadoop是用于实现这个概念的技术。
湖仓一体(Data Lakehouse)的概念,旨在为企业提供一个统一的、可共享的数据底座,避免传统的数据湖、数据仓库之间的数据移动,将原始数据、加工清洗数据、模型化数据,共同存储于一体化的“湖仓”中,既能面向业务实现高并发、精准化、高性能的历史数据、实时数据的查询服务,又能承载分析报表、批处理、数据挖掘等分析型业务。

数据仓库是存储和处理结构化数据,数据湖是存储结构化和非结构化数据,并具备单独处理结构化数据和单独处理非结构化数据的能力,湖仓一体是存储结构化和非结构化数据,并统一处理结构化和非结构化数据
Snowflake
Databricks
众所周知,CDH是市场上最受欢迎的免费Hadoop版本之一。目前,市场上免费Hadoop版本主要有三个,分别是Apache版本(开源社区版,也是最原始的版本,其他所有发行版均基于这个版本进行改进)、Cloudera版本(简称CDH)、Hortonworks版本(简称HDP,2018年Cloudera与Hortonworks合并后归属于Cloudera)。Cloudera对HDP的技术支持已经于2021年12月结束,Cloudera 还宣布今后将不再推出新版本的CDH和HDP,也就是这两个Hadoop版本不会再演进了。这就意味着,今后企业想要部署免费Hadoop平台只能选择社区版本,显然这会提高Hadoop部署和运维的难度和技术门槛。
Cloudera、Hortonworks、MapR是其中最有影响的三个,被称为“Hadoop三巨头”:2008年Cloudera成立,2009年MapR 成立,2011年Hortonworks 成立。
后来“Hadoop三巨头”的发展都不太顺利,争议也一直无法平息。2018年10月,无法实现盈利的Cloudera和Hortonworks宣布平等合并,Cloudera以股票方式收购Hortonworks,Cloudera股东获得Hortonworks 60%的股份。2019年,HPE宣布收购MapR 的资产,收购金额未对外公开。此前MapR已经陷入财务困境,对外表示再没有融资将面临倒闭的命运。
合并后的Cloudera做出了一些战略调整,其中包括对CDH/HDP的支持政策。Cloudera宣布在2022年3月停止CDH、HDP的技术支持和版本更新,还宣布不会再推出新版本的CDH和HDP。另外,Cloudera的代码开源政策也做了调整,从2021年年初开始就已经停止了免费下载CDH、HDP。
Cloudera是Hadoop社区的“顶梁柱”,拥有CDH、HDP这两个市场上最受认可的开源发行版,Cloudera的一举一动对Hadoop影响不言而喻。Cloudera对CDH、HDP政策调整意味着今后要用免费的Hadoop基本只有Apache社区版了,而社区版无论稳定性和安全性与CDH、HDP都不在一个水平上,如果要用于生产环境需要进行多个模块的集成和大量二次开发,这个工作对技术人员要求非常高。可以预料,未来Hadoop的社区热度和应用会受到不小影响,这也是人们对Hadoop的未来前景产生担忧的原因所在。
对Hadoop的第二个批评是其技术过时,主要指MapReduce只能进行批处理,无法处理实时应用。MapReduce的确有这方面的弱点。实际上,这一点如今已不是一个问题,每个技术都有自己最佳的适用场景,如果要实时处理可以用Spark,要处理流数据有Flink,这些都可以在Hadoop框架之下很好地进行集成。Hadoop萌芽于2004年,2008年左右以Hadoop之名被开源,其核心技术也诞生于那个时代,用今天的需求来要求Hadoop并不合理。而且,Hadoop本身也不断演进,比如积极拥抱Spark、Kubernetes、Kafka等,为企业提供一个更好的大数据平台框架。
唱衰Hadoop的第三原因是云计算的崛起。众所周知,HDFS是Hadoop最为核心的两个模块之一(另一个是MapReduce),也是Hadoop的根基。而云服务的崛起使得以S3为代表的对象存储开始流行,云服务商结合对象存储推出的各种Hadoop云服务,相比于传统方式部署的 Hadoop更简单易用。比如AWS的Elastic Map Reduce (EMR)非常简单,而且与底层S3存储完全集成,具有较低的购置成本并且更便宜。
其实,经过多年的发展,在Hadoop生态体系中很多模块已经被新的模块替换,比如Spark替代MapReduce、S3替代HDFS、K8s替代Yarn,而完成了这些替代之后的Hadoop也早就是不是原来的Hadoop了。
应该说,和所有创新技术一样,Hadoop也有自己的生命周期。当IT环境发生了变化,比如,今天云计算环境正在成为企业标准IT环境,早期Hadoop所强调的存算一体正在被越来越多的存算分离场景所取代;实时数仓、湖仓一体正在成为行业趋势的时候,Hadoop虽然自己也在与时俱进,终究会被更新、更好的技术替代。
大数据产业的发展必然带来对大数据平台的需求,面对强劲的市场需求,在后Hadoop时代,我们该选择什么样的大数据平台?特别是那些已经部署了CDH、HDP和各种Hadoop版本的用户怎么办?
如果公司技术实力够用,当然还是可以继续跟踪Hadoop社区版本,结合社区和自己的技术力量来解决各种难题,特别是如果大数据平台能够满足目前自己需求的前提之下。但是,对于更多普通企业用户,自己的技术实力不够,付费寻求技术支持可能会是更好的选择。好在目前在Hadoop这个大数据生态体系之中,有不少颇有技术实力的第三方提供自己的Hadoop版本和服务,比如华为、阿里云等。
而对于那些已经部署Cloudera的CDH和HDP企业而言,选择升级到Cloudera的新一代数据云平台CDP也是一个不错的选择。CDP是Cloudera2019年面向云环境推出的一个大数据处理平台。根据Cloudera大中华区技术总监刘隶放的说法,CDP可以提供六大能力:第一个是提供数据中心(Data Hub) 的能力,也就是提供一个基础性的集中存放数据、管理数据的能力;第二个是Data Flow & Streaming,包括用于数据收集和流式的实时数据处理的一整套产品。第三个是Cloudera Data Engineering,主要是用来进行批量数据处理。第四个是ClouderaData Warehouse,也就是数据仓库,可以替换原有的传统数据仓库。第五个是Operational Database,基于HBase等一些实时的非结构化的数据库,提供互联网级别的对外服务。第六个是机器学习的平台。
分区数量调整
从函数接口可以看到,reparation是直接调用coalesce(numPartitions, shuffle=True),不同的是,reparation函数可以增加或减少 partition 数量,调用repartition函数时,还会产生shuffle操作。而coalesce函数可以控制是否shuffle,但当shuffle为False时,只能减小partition数,而无法增大。
DAGScheduler 将一个 TaskSet 交给 TaskScheduler 后,TaskScheduler 会为每个 TaskSet 进行任务调度,Spark 中的任务调度分为两种:FIFO(先进先出)调度和 FAIR(公平调度)调度。
FIFO 调度:即谁先提交谁先执行,后面的任务需要等待前面的任务执行。这是 Spark 的默认的调度模式。
FAIR 调度:支持将作业分组到池中,并为每个池设置不同的调度权重,任务可以按照权重来决定执行顺序。
在 Spark 中使用哪种调度器可通过配置spark.scheduler.mode参数来设置,可选的参数有 FAIR 和 FIFO,默认是 FIFO。
Driver初始化SparkContext过程中,会分别初始化DAGScheduler、TaskScheduler、SchedulerBackend以及HeartbeatReceiver,并启动SchedulerBackend以及HeartbeatReceiver。
SchedulerBackend通过ApplicationMaster申请资源,并不断从TaskScheduler中拿到合适的Task分发到Executor执行。
HeartbeatReceiver负责接收Executor的心跳信息,监控Executor的存活状况,并通知到TaskScheduler。
DAGScheduler负责Stage级的调度,根据RDD的DAG切分为若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度。具体的划分策略是:以shuffle(宽依赖)为界划分Stage,窄依赖的RDD会被分到用一个Stage中,可以进行pipeline式的计算。划分的Stages分两类,一类叫做ResultStage,为DAG最下游的Stage,由Action方法决定,另一类叫做ShuffleMapStage,为下游Stage准备数据。
TaskScheduler负责Task级的调度,将DAGScheduler传过来的TaskSet封装为TaskSetManager作为单元进行调度,调度过程中SchedulerBackend负责提供可用资源executor,task会被发送到executor进行执行