待深入分析
https://bigbully.github.io/Dapper-translation/
https://github.com/bigbully/Dapper-translation/tree/gh-pages
https://tech.ipalfish.com/blog/2020/12/29/design-dimensions-of-tracing-systems/
https://tech.ipalfish.com/blog/2021/03/04/implementing-tail-based-sampling/
https://tech.ipalfish.com/blog/2023/06/25/apm/
https://chenquan.me/posts/tracing-system-analysis/
https://www.thebyte.com.cn/Observability/summary.html
https://icyfenix.cn/distribution/observability/
https://icyfenix.cn/distribution/observability/logging.html
https://icyfenix.cn/distribution/observability/tracing.html
分布式链路追踪系统
分布式调用链路

trace,追踪
系统中从源请求方发起的请求会在分布式系统中形成一个调用链路,该调用链路会被分配一个trace_id,用以标识整个调用链路的追踪数据。
trace id 为分布式id
而被请求的接口收到请求时,如果请求传递了TraceID,那么被请求的服务会继续使用传递过来的TraceID,如果请求没有TraceID则自己生成一个
span,跨度
调用链中每两个节点间为一个 span,span 可以使用 spanid或者 RPCID 标识。
span id
span id 方案中 span id 记录当前 span 标识,由 parent_id 记录其父标识,由此构建调用链。

RPCID,层级计数器
第一个接口生成RPCID为 1.1 ,RPCID的 前缀 是1, 计数器 是1(日志记录为 1.1)。
当所在接口请求其他接口或数据服务(MySQL、Redis、API、Kafka)时, 计数器 +1,并在请求当中带上1.2这个数值(因为当前的 前缀 + “.” + 计数器值 = 1.2),等到返回结果后,继续请求下一个资源时继续+1,期间产生的任何日志都会记录当前 前缀 +“.”+ 计数器值。
每一层收到了前缀后,都在后面加了一个累加的计数器

而被请求的接口收到请求时,如果传递了RPCID,那么被请求的服务会将传递来的RPCID当作前缀,计数器从1开始计数。
相对于span,通过这个层级计数器做出来的RPCID有两个优点。
第一个优点是我们可以记录请求方日志,如果被请求方没有记录日志,那么还可以通过请求方日志观测分析被调用方性能(MySQL、Redis)。
另一个优点是哪怕日志收集得不全,丢失了一些,我们还可以通过前缀有几个分隔符,判断出日志所在层级进行渲染。举个例子,假设我们不知道上图的1.5.1是谁调用的,但是根据它的UUID和层级1.5.1这些信息,渲染的时候,我们仍旧可以渲染它大概的链路位置。
trace_id、span_id/RPCID存储到什么中以实现链路追踪呢?
- HTTP协议放在Header;
- RPC协议放在meta中传递;
- 队列可以放在消息体的Header中,或直接在消息体中传递;
- 其他特殊情况下可以通过网址请求参数传递。
那么应用内多线程和多协程之间如何传递TraceID呢?一般来说,我们会通过复制一份Context传递进入线程或协程,并且如果它们之前是并行关系,我们复制之后需要对下发之前的RPCID计数器加1,并把前缀和计数器合并成新的前缀,以此区分并行的链路。
除此之外,我们还做了一些特殊设计,当我们的请求中带一个特殊的密语,并且设置类似X-DEBUG Header等于1时,我们可以开启在线debug模式,在被调用接口及所有依赖的服务都会输出debug级别的日志,这样我们临时排查线上问题会更方便。
日志类型定义
可以说,只要让日志输出当前的TraceId和RPCID(SpanID),并在请求所有依赖资源时把计数传递给它们,就完成了大部分的分布式链路跟踪。下面是我定制的一些日志类型和日志格式,供你参考:
## 日志类型
* request.info 当前被请求接口的相关信息,如被请求接口,耗时,参数,返回值,客户端信息
* mysql.connect mysql连接时长
* mysql.connect.error mysql链接错误信息
* mysql.request mysql执行查询命令时长及相关信息
* mysql.request.error mysql操作时报错的相关信息
* redis.connect redis 链接时长
* redis.connect.error redis链接错误信息
* redis.request redis执行命令
* redis.request.error redis操作时错误
* memcache.connect
* memcache.connect.error
* memcache.request.error
* http.get 另外可以支持restful操作get put delete
* http.post
* http.*.error
## Metric日志类型
* metric.counter
...略
## 分级日志类型
* log.debug: debug log
* log.trace: trace log
* log.notice: notice log
* log.info: info log
* log.error: application error log
* log.alarm: alarm log
* log.exception: exception log
你会发现,所有对依赖资源的请求都有相关日志,这样可以帮助我们分析所有依赖资源的耗时及返回内容。此外,我们的分级日志也在trace跟踪范围内,通过日志信息可以更好地分析问题。而且,如果我们监控的是静态语言,还可以像之前说的那样,对一些模块做Metrics,定期产生日志。
日志格式样例
日志建议使用JSON格式,所有字段除了标注为string的都建议保存为字符串类型,每个字段必须是固定数据类型,选填内容如果没有内容就直接不输出。
这样设计其实是为了适配Elasticsearch+Kibana,Kibana提供了日志的聚合、检索、条件检索和数值聚合,但是对字段格式很敏感,不是数值类型就无法聚合对比。
下面我给你举一个例子用于链路跟踪和监控,你主要关注它的类型和字段用途。
{
"name": "string:全量字段介绍,必填,用于区分日志类型,上面的日志列表内容写这里",
"trace_id": "string:traceid,必填",
"rpc_id": "string:RPCID,服务端链路必填,客户端非必填",
"department":"部门缩写如client_frontend 必填",
"version": "string:当前服务版本 cpp-client-1.1 php-baseserver-1.4 java-rti-1.9,建议都填",
"timestamp": "int:日志记录时间,单位秒,必填",
"duration": "float:消耗时间,浮点数 单位秒,能填就填",
"module": "string:模块路径,建议格式应用名称_模块名称_函数名称_动作,必填",
"source": "string:请求来源 如果是网页可以记录ref page,选填",
"uid": "string:当前用户uid,如果没有则填写为 0长度字符串,可选填,能够帮助分析用户一段时间行为",
"pid": "string:进程pid,如果没有填写为 0长度字符串,如果有线程可以为pid-tid格式,可选填",
"server_ip": "string 当前服务器ip,必填",
"client_ip": "string 客户端ip,选填",
"user_agent": "string curl/7.29.0 选填",
"host": "string 链接目标的ip及端口号,用于区分环境12.123.23.1:3306,选填",
"instance_name": "string 数据库连接配置的标识,比如rti的数据库连接,选填",
"db": "string 数据库名称如:peiyou_stastic,选填",
"code": "string:各种驱动或错误或服务的错误码,选填,报错误必填",
"msg": "string 错误信息或其他提示信息,选填,报错误必填",
"backtrace": "string 错误的backtrace信息,选填,报错误必填",
"action": "string 可以是url、sql、redis命令、所有让远程执行的命令,必填",
"param": "string 通用参数模板,用于和script配合,记录所有请求参数,必填",
"file": "string userinfo.php,选填",
"line": "string 232,选填",
"response": "string:请求返回的结果,可以是本接口或其他资源返回的数据,如果数据太长会影响性能,选填",
"response_length": "int:相应内容结果的长度,选填",
"dns_duration": "float dns解析时间,一般http mysql请求域名的时候会出现此选项,选填",
"extra": "json 放什么都可以,用户所有附加数据都扔这里"
}
## 样例
被请求日志
{
"x_name": "request.info",
"x_trace_id": "123jiojfdsao",
"x_rpc_id": "0.1",
"x_version": "php-baseserver-4.0",
"x_department":"tal_client_frontend",
"x_timestamp": 1506480162,
"x_duration": 0.021,
"x_uid": "9527",
"x_pid": "123",
"x_module": "js_game1_start",
"x_user_agent": "string curl/7.29.0",
"x_action": "http://testapi.speiyou.com/v3/user/getinfo?id=9527",
"x_server_ip": "192.168.1.1:80",
"x_client_ip": "192.168.1.123",
"x_param": "json string",
"x_source": "www.baidu.com",
"x_code": "200",
"x_response": "json:api result",
"x_response_len": 12324
}
### mysql 链接性能日志
{
"x_name": "mysql.connect",
"x_trace_id": "123jiojfdsao",
"x_rpc_id": "0.2",
"x_version": "php-baseserver-4",
"x_department":"tal_client_frontend",
"x_timestamp": 1506480162,
"x_duration": 0.024,
"x_uid": "9527",
"x_pid": "123",
"x_module": "js_mysql_connect",
"x_instance_name": "default",
"x_host": "12.123.23.1:3306",
"x_db": "tal_game_round",
"x_msg": "ok",
"x_code": "1",
"x_response": "json:****"
}
### Mysql 请求日志
{
"x_name": "mysql.request",
"x_trace_id": "123jiojfdsao",
"x_rpc_id": "0.2",
"x_version": "php-4",
"x_department":"tal_client_frontend",
"x_timestamp": 1506480162,
"x_duration": 0.024,
"x_uid": "9527",
"x_pid": "123",
"x_module": "js_game1_round_sigup",
"x_instance_name": "default",
"x_host": "12.123.23.1:3306",
"x_db": "tal_game_round",
"x_action": "select * from xxx where xxxx",
"x_param": "json string",
"x_code": "1",
"x_msg": "ok",
"x_response": "json:****"
}
### http 请求日志
{
"x_name": "http.post",
"x_trace_id": "123jiojfdsao",
"x_department":"tal_client_frontend",
"x_rpc_id": "0.3",
"x_version": "php-4",
"x_timestamp": 1506480162,
"x_duration": 0.214,
"x_uid": "9527",
"x_pid": "123",
"x_module": "js_game1_round_win_report",
"x_action": "http://testapi.speiyou.com/v3/game/report",
"x_param": "json:",
"x_server_ip": "192.168.1.1",
"x_msg": "ok",
"x_code": "200",
"x_response_len": 12324,
"x_response": "json:responsexxxx",
"x_dns_duration": 0.001
}
### level log info日志
{
"x_name": "log.info",
"x_trace_id": "123jiojfdsao",
"x_department":"tal_client_frontend",
"x_rpc_id": "0.3",
"x_version": "php-4",
"x_timestamp": 1506480162,
"x_duration": 0.214,
"x_uid": "9527",
"x_pid": "123",
"x_module": "game1_round_win_round_end",
"x_file": "userinfo.php",
"x_line": "232",
"x_msg": "ok",
"x_code": "201",
"extra": "json game_id lesson_num xxxxx"
}
### exception 异常日志
{
"x_name": "log.exception",
"x_trace_id": "123jiojfdsao",
"x_department":"tal_client_frontend",
"x_rpc_id": "0.3",
"x_version": "php-4",
"x_timestamp": 1506480162,
"x_duration": 0.214,
"x_uid": "9527",
"x_pid": "123",
"x_module": "game1_round_win",
"x_file": "userinfo.php",
"x_line": "232",
"x_msg": "exception:xxxxx call stack",
"x_code": "hy20001",
"x_backtrace": "xxxxx.php(123) gotError:..."
}
### 业务自发告警日志
{
"x_name": "log.alarm",
"x_trace_id": "123jiojfdsao",
"x_department":"tal_client_frontend",
"x_rpc_id": "0.3",
"x_version": "php-4",
"x_timestamp": 1506480162,
"x_duration": 0.214,
"x_uid": "9527",
"x_pid": "123",
"x_module": "game1_round_win_round_report",
"x_file": "game_win_notify.php",
"x_line": "123",
"x_msg": "game report request fail! retryed three time..",
"x_code": "201",
"x_extra": "json game_id lesson_num xxxxx"
}
### matrics 计数器
{
"x_name": "metrix.count",
"x_trace_id": "123jiojfdsao",
"x_department":"tal_client_frontend",
"x_rpc_id": "0.3",
"x_version": "php-4",
"x_timestamp": 1506480162,
"x_uid": "9527",
"x_pid": "123",
"x_module": "game1_round_win_click",
"x_extra": "json curl invoke count"
}
这个日志不仅可以用在服务端,还可以用在客户端。客户端每次被点击或被触发时,都可以自行生成一个新的TraceID,在请求服务端时就会带上它。通过这个日志,我们可以分析不同地域访问服务的性能,也可以用作用户行为日志,仅仅需添加我们的日志类型即可。
上面的日志例子基本把我们依赖的资源情况描述得很清楚了。另外,我补充一个技巧,性能记录日志可以将被请求的接口也记录成一个日志,记录自己的耗时等信息,方便之后跟请求方的请求日志对照,这样可分析出两者之间是否有网络延迟等问题。
除此之外,这个设计还有一个核心要点:研发并不一定完全遵守如上字段规则生成日志,业务只要保证项目范围内输出的日志输出所有必填项目(TraceID,RPCID/SpanID,TimeStamp),同时保证数值型字段功能及类型稳定,即可实现trace。
我们完全可以汇总日志后,再对不同的日志字段做自行解释,定制出不同业务所需的统计分析,这正是ELK最强大的地方。
为什么大部分设计都是记录依赖资源的日志呢?原因在于在没有IO的情况下,程序大部分都是可控的(侧重计算的服务除外)。只有IO类操作容易出现不稳定因素,并且日志记录过多也会影响系统性能,通过记录对数据源的操作能帮助我们排查业务逻辑的错误。
我们刚才提到日志如果过多会影响接口性能,那如何提高日志的写吞吐能力呢?这里我为你归纳了几个注意事项和技巧:
1.提高写线程的个数,一个线程写一个日志,也可以每个日志文件单独放一个磁盘,但是你要注意控制系统的IOPS不要超过100;
2.当写入日志长度超过1kb时,不要使用多个线程高并发写同一个文件。原因参考 append is not Atomic,简单来说就是文件的append操作对于写入长度超过缓冲区长度的操作不是原子性的,多线程并发写长内容到同一个文件,会导致日志乱序;
3.日志可以通过内存暂存,汇总达到一定数据量或缓存超过2秒后再落盘,这样可以减少过小日志写磁盘系统的调用次数,但是代价是被强杀时会丢日志;
4.日志缓存要提前malloc使用固定长度缓存,不要频繁分配回收,否则会导致系统整体缓慢;
5.服务被kill时,记得拦截信号,快速fsync内存中日志到磁盘,以此减少日志丢失的可能。
系统可观测性,Observability
系统可观测性是指系统能够通过输出数据(如日志、指标、追踪等)而被外部观测到其自身内部状态的能力。
外部用户通过系统输出数据观测到系统内部状态越详细越精确,表明该系统可观测性能力越强。
遥测数据,telemetry data
传感器、软件和其他监测工具收集的包括日志、指标、事件以及系统、应用程序或设备创建的任何其他痕迹数据。
Distributed Tracing
有哪些数据

在此之前,常见监控系统主要有三种类型:Metrics、Tracing和Logging。
- Metrics:可聚合的数据,通常包括计数器(Counter)、量表(Gauge)和直方图(Histogram)等,用于度量和观察系统的行为。Metrics可以用来衡量一个系统的性能,例如请求的数量、响应的时间等。
常见的开源Metrics有Zabbix、Nagios、Prometheus、InfluxDb、OpenFalcon,主要做各种量化指标汇总统计,比如监控系统的容量剩余、每秒请求量、平均响应速度、某个时段请求量多少。

- Tracing:指使用特定的日志记录程序的执行信息,记录单个请求的处理流程,包括服务调用和处理时长等信息,用于诊断和优化分布式系统。
- 常见的开源链路跟踪有Jaeger、Zipkin、Pinpoint、Skywalking,主要是通过分析每次请求链路监控分析的系统,我么可以通过TraceID查找一次请求的依赖及调用链路,分析故障点和传导过程的耗时。

- Logging:用于记录离散的事件,包含程序执行到某一点或某一阶段的详细信息。Logging可以用来记录程序的行为,帮助开发人员调试和解决问题。
而常见的开源Logging有ELK、Loki、Loggly,主要是对文本日志的收集归类整理,可以对错误日志进行汇总、警告,并分析系统错误异常等情况。

这三种监控系统可以说是大服务集群监控的主要支柱,它们各有优点,但一直是分别建设的。这让我们的系统监控存在一些割裂和功能重复,而且每一个标准都需要独立建设一个系统,然后在不同界面对同一个故障进行分析,排查问题时十分不便。
Tracing、Metrics和Logging这三种监控类型交集的情况比较常见:
- Logging&Metrics:Metrics提供系统层面的统计数据,如系统总请求量、响应时间等;logging则提供系统的详细行为,比如统计某段时间SQL各类请求访问的总数等;
- Metrics&Tracing:Metrics可以看做是宏观层面的tracing,tracing更关注微观层面某个请求的处理流程、处理时间等,比如单个请求中SQL执行时长、gpc调用次数等;
- Tracing&Logging:Logging记录的是一些离散的事件、tracing则是记录的这些请求的处理过程,比如在请求过程中详细的处理记录日志等信息。
三位一体的标准应运而生,这就是 OpenTelemetry 标准(集成了OpenCensus、OpenTracing标准)。这个标准将Metrics+Tracing+Logging集成一体,这样我们监控系统的时候就可以通过三个维度综合观测系统运转情况。
常见OpenTelemetry开源项目中的Prometheus、Jaeger正在遵循这个标准逐步改进实现OpenTelemetry 实现的结构如下图所示:

事实上,分布式链路跟踪系统及监控主要提供了以下支撑服务:
- 监控日志标准
- 埋点SDK(AOP或侵入式)
- 日志收集
- 分布式日志传输
- 分布式日志存储
- 分布式检索计算
- 分布式实时分析
- 个性化定制指标盘
- 系统警告
我建议使用ELK提供的功能去实现分布式链路跟踪系统,因为它已经完整提供了如下功能:
- 日志收集(Filebeat)
- 日志传输(Kafka+Logstash)
- 日志存储(Elasticsearch)
- 检索计算(Elasticsearch + Kibana)
- 实时分析(Kibana)
- 个性定制表格查询(Kibana)
这样一来,我只需要制定日志格式、埋点SDK,即可实现一个具有分布式链路跟踪、Metrics、日志分析系统。
事实上,Log、Metrics、trace三种监控体系最大的区别就是日志格式标准,底层实现其实是很相似的。既然ELK已提供我们需要的分布式相关服务,下面我简单讲讲日志格式和SDK埋点,通过这两个点我们就可以窥见分布式链路跟踪的全貌。
TraceID单次请求标识
可以说,要想构建一个简单的Trace系统,我们首先要做的就是生成并传递TraceID。

有哪些处理步骤
采集、传输、存储、分析
采集
由于每一个请求都会生成一个链路,为了减少性能消耗,避免存储资源的浪费,dapper并不会上报所有的span数据,而是使用采样的方式。举个例子,每秒有1000个请求访问系统,如果设置采样率为1/1000,那么只会上报一个请求到存储端。
存储
链路中的span数据经过收集和上报后会集中存储在一个地方,Dapper使用了BigTable数据仓库,常用的存储还有ElasticSearch, HBase, In-memory DB等。
TraceId和SpanId
- TraceId
TraceId即跟踪Id。在分布式架构中,每个请求会生成一个全局的唯一性Id,通过这个Id可以串联起整个调用链,也就是说请求在分布式系统内部流转时,系统需要始终保持传递该唯一性Id,直到请求返回。这个唯一性Id就是TraceId。
- SpanId
除了TraceId外,我们还需要SpanId,SpanId一般被称为跨度Id。所谓跨度,就是调用链路中的其中一段时间,具有明确的开始和结束这两个节点,这样通过计算开始时间和结束时间之间的时间差,我们就能明确调用过程在这个Span上所产生的时间延迟。
通过前面的介绍,我们不难理解TraceId和SpanId之间是一对多的关系,即在一个调用链路中只会存在一个TraceId,但会存在多个Span。这样多个SpanId之间就会有父子关系,即链路中的前一个SpanId是后一个SpanId的父SpanId。
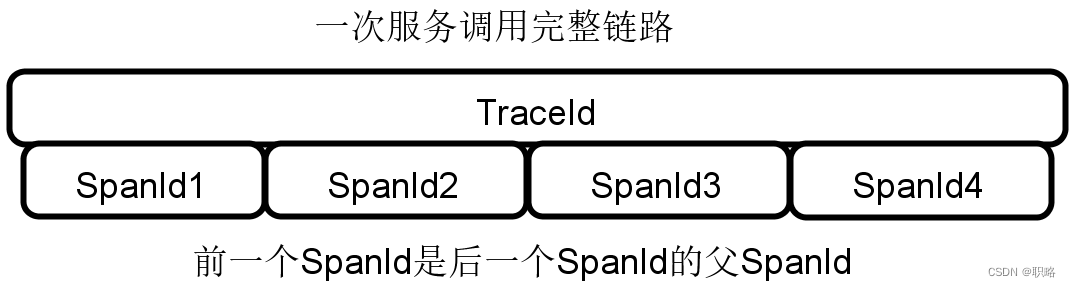
四种注解
理解了TraceId和SpanId的概念之后,我们就需要对整个分布式调用链路进行进一步拆分,从而细化控制的粒度。业界一般通过四种不同的注解(Annotation)记录每个服务的客户端请求和服务器响应过程。
- cs注解
cs 代表Client Send,即客户端发送请求,启动整个调用链路。
- sr注解
sr 代表Server Receive,即服务端接收请求。显然,(sr-cs)值代表请求从客户端到服务器端所需要的网络传输时间。
- ss注解
ss 代表Server Send,即服务端把请求处理结果返回给客户端。(ss-sr)值代表服务器端处理该请求所需要的时间。
- cr注解
cr 代表Client Receive,即客户端接收到服务端响应,结束调用链路。(cr-sr)值代表响应结果从服务器端传输到客户端所需要的时间。
下面结合一张示意图来进一步解释这四种注解之间的关联关系。
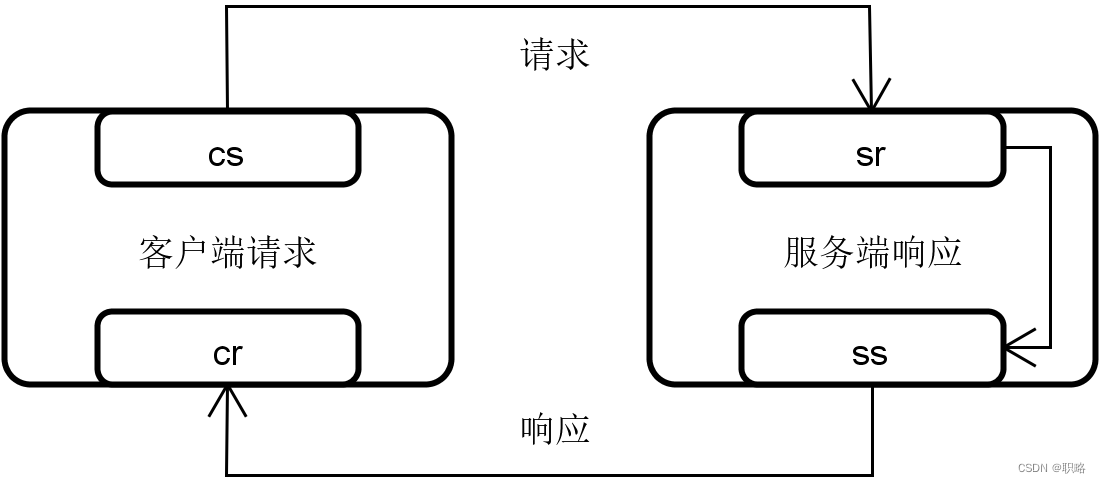
有了这四个注解之后,我们就可以使用它们来量化整个服务调用链路,从而找出潜在的问题。这里同样给出一个示意图。

在上图中,我们看到这次请求的TraceId是trace1,而SpanId根据不同的服务会发生变化。而四种注解构成了客户端和服务器对一次请求处理的闭环,对于服务A而言,cs是11:10:44, cr是11:10:55,也就说该次服务请求经由服务A的整个调用链路时间是11s(11:10:44-11:10:55),显然这个响应时间非常长。
「Zipkin(Twitter)」
Zipkin是Twitter基于Google Dapper开发的开源调用链追踪系统,几乎完全按照Dapper中定义的追踪数据格式,追踪方式和架构进行了实现
Zipkin整个架构上与Dapper非常类似,装配了追踪工具的服务将追踪信息上报给Transport,Collector对追踪信息进行处理,存储,然后前端调用存储中的信息进行展示,其中Transport支持(HTTP, Kafka,Scribe),Storage支持(Mysql, ElasticSearch,Cassandra)- 开发语言:Java
- 是否开源:是,代码地址:https://github.com/openzipkin/zipkin
- 业务接入方式:使用Zipkin的装配工具
- 功能:提供了调用链的查询,依赖分析功能,并提供了比较丰富的装配工具
- 支持追踪的服务:Zipkin的追踪是独立于开发语言的,只要满足Zipkin的追踪数据格式就可以,已经支持的框架包括:grpc,Jersey,Spring Web,Spring boot,Spring Cloud,Mysql,okHttp,Sevlet,JAXRS2等
- 优缺点:
- 优点:独立于开发语言,对应用侵入非常小,提供服务之间的依赖关系展示。
- 缺点:需要不断的支持新的框架,开发者需要加入少量的代码,应用追踪数据的上报对Zipkin的后台的稳定性有比较强的依赖,缺乏宏观监控
「jaeger(Uber)」
jaeger 是Uber基于Google Dapper,并借鉴Zipkin使用GO语言开发的开源调用链追踪系统,架构,功能与Zipkin类似,也能与Zipkin的追踪数据兼容
jaeger的整体架构与Zipkin类似,在Zipkin的基础上实现了自适应的采样,通过Thrift RPC上传追踪数据。利用Spark定期的处理追踪数据,分析服务之间的依赖关系,这个功能Zipkin也具备- 开发语言:GO
- 是否开源:是,代码地址:https://github.com/uber/jaeger
- 业务接入方式:使用jaeger提供的装配工具
- 功能:提供了调用链的查询,依赖分析功能
- 支持追踪的服务:jaeger的追踪是独立于开发语言的,提供了GO,Java,Node.js和python的装配工具SDK,可以直接追踪的框架包括dropwizard,ApacheHTTPClient,JAXRS2
- 优缺点:
- 优点:独立于开发语言,提供了服务之间的依赖关系展示,提供了自适应的采样功能,具有服务级别平均延时的宏观监控
- 缺点:能够直接追踪的框架还比较少,很多都是要调用SDK直接埋点,应用追踪数据的上报对jaeger的后台的稳定性有比较强的依赖
2010年 Google论文 Dapper, a Large-Scale Distributed Systems Tracing Infrastructure 阐述了分布式链路追踪的主要设计思路,由此衍生一系列分布式链路追踪系统。
- 低开销:追踪系统对正在运行的服务应该具备很小的性能影响。
- 应用层透明性:开发人员无需关注追踪系统,尽可能减少对业务系统的代码侵入性。
- 可扩展性:支持分布式部署,具备良好的扩展性,能处理服务和集群的规模。
- 数据的快速分析:追踪数据生成后的数据分析要快,分析维度尽可能多,理想情况下是一分钟内,数据的新鲜度能快速对生产异常做出反应。
链路追踪的概念
从 广义 上,分布式链路追踪系统可以分为三个部分:数据收集、数据存储、数据展示。
从 狭义 上,指链路追踪的 数据收集 部分,例如 Spring Cloud Sleuth 就属于狭义的追踪系统,通常会搭配 Zipkin 作为数据展示,搭配 Elasticsearch 作为数据存储来组合使用。
- Trace(追踪):一个完整的用户请求流程,从用户发起请求开始,到请求结束。一个追踪包含多个 Span。
- Span(跨度):一种表示工作单元的结构,通常对应着请求经过的某个服务或者操作,每个 Span 包含以下信息:
- Span ID:唯一标识当前 Span
- Trace ID:标识属于同一个 Trace 的所有 Span
- 父 Span ID:如果当前 Span 由另一个 Span 引发,则会记录父 Span ID
- 时间戳、标签和日志
每一次 Trace 是由若干个有顺序、有层级关系的 Span 组成的一棵追踪树结构。

生产环境的链路追踪系统,主要分为以下四个大模块:
4.1 埋点与生成日志
- 分客户端埋点、服务端埋点以及客户端和服务端双向埋点。
- 埋点日志通常包含:Trace ID、Span ID、调用的开始时间、协议类型、调用方 IP 和端口、请求的服务名、调用耗时、调用结果、异常信息等。
- 在高并发服务中,通常使用采样 + 异步日志的方式解决性能问题。
4.2 收集和存储日志
- 需支持分布式日志采集方案,一般会用消息队列(MQ)作为缓冲。
- 每个机器上有一个后台服务进程(daemon),专门用于日志收集和 Trace 转发。
- 使用多级 collector,类似发布/订阅架构,可以负载均衡。
- 聚合数据进行实时分析和离线存储,离线分析需将同一条调用链的日志汇总在一起。
4.3 分析和统计调用链数据
- 调用链跟踪分析:把同一 Trace ID 的 Span 收集起来,按时间排序就是 timeline,把 Parent ID 串起来就是调用栈。
4.4 数据展现以及决策支持
…
数据收集的三种实现方式
无论是狭义还是广义的链路追踪系统,都必须包含数据收集的工作,以下是三种主流的数据收集方式:
5.1 基于日志的追踪(Log-based Tracing)
- 将 Trace、Span 等信息直接输出到应用日志中,然后将日志归集过程汇聚到一起,再从全局日志信息中反推出完整的调用链拓扑关系。
- 对网络消息完全没有侵入性,对应用程序只有很少量的侵入性,对性能的影响非常低。
- 缺点:
- 依赖日志归集过程,日志不绝对一致和连续,精准性较低。
- 业务服务的调度和日志归集不是由同一个进程同时完成的,存在日志延迟或丢失的问题,从而产生追踪失真的情况。
5.2 基于服务的追踪
- 目前最常见的追踪实现方式,如 Zipkin、SkyWalking、Pinpoint 等主流追踪系统都采用这种方式。
- 实现思路是通过某些手段给目标应用注入追踪探针(Probe),比如针对 Java 应用,一般通过 Java Agent 注入。
- 探针可以看作是目标服务身上的小型微服务系统,有服务注册、心跳检测等功能,有专门的数据收集协议,可以把从目标系统收集的服务调用信息,通过 HTTP 或者 RPC 请求发送给追踪系统。
- 该方式具备追踪的精确性和稳定性,缺点是消耗的资源更多,具备更强的侵入性。
OpenTracing
OpenTracing通过提供平台无关、厂商无关的API,使得开发人员能够方便的添加(或更换)追踪系统的实现。
OpenCensus
OpenTelemetry
CNCF,云原生计算基金会
由 OpenTracing 和 OpenCensus 合并而来。
- OpenTelemetry 可以用于从应用程序收集数据,是一组工具、API 和 SDK 集合,用于检测、生成、收集和导出遥测数据(指标、日志和追踪),以帮助分析应用的性能和行为。
- 具体解释如下:
- 一个可观测性框架和工具包,旨在创建和管理遥测数据,如追踪、指标和日志。
- 与供应商和工具无关,可以与各种可观测性后端一起使用,包括开源工具如 Jaeger 和 Prometheus,以及商业产品。
- 不是像 Jaeger、Prometheus 或其他商业供应商那样的可观测性后端。
- 专注于遥测的生成、收集、管理和导出。OpenTelemetry 的一个主要目标是能够轻松地在应用程序或系统中插桩,无论它们使用何种语言、基础设施或运行时环境。遥测的数据存储和可视化故意留给其他工具。

-
Zipkin 是对 Dapper 的一个开源实现
span 采集方式
trace id 唯一保证
4、请求量这么多,全部采集会不会影响性能?
如果对每个请求调用都采集,那毫无疑问数据量会非常大,但反过来想一下,是否真的有必要对每个请求都采集呢?其实没有必要,我们可以设置采样频率,只采样部分数据,SkyWalking 默认设置了 3 秒采样 3 次,其余请求不采样,如图所示:

这样的采样频率其实足够我们分析组件的性能了,按 3 秒采样 3 次,这样的频率来采样数据会有啥问题呢。理想情况下,每个服务调用都在同一个时间点,这样的话每次都在同一时间点采样确实没问题。如下图所示:

但在生产上,每次服务调用基本不可能都在同一时间点调用,因为期间有网络调用延时等,实际调用情况很可能是下图这样:

这样的话就会导致某些调用在服务 A 上被采样了,在服务 B,C 上不被采样,也就没法分析调用链的性能。
那么 SkyWalking 是如何解决的呢?
它是这样解决的:如果上游有携带 Context 过来(说明上游采样了),则下游将强制采集数据,这样可以保证链路完整。
OpenTelemetry
https://www.xiaoyizhiqu.com/xyzq_news/article/678d22244ddd79f11a449ed1
ref