Redis到底是单线程还是多线程?
如果仅仅聊Redis的核心业务部分(命令处理),答案是单线程
如果是聊整个Redis,那么答案就是多线程
在Redis版本迭代过程中,在两个重要的时间节点上引入了多线程的支持:
Redis v4.0:引入多线程异步处理一些耗时较旧的任务,例如异步删除命令unlink
Redis v6.0:在核心网络模型中引入 多线程,进一步提高对于多核CPU的利用率
因此,对于Redis的核心网络模型,在Redis 6.0之前确实都是单线程。是利用epoll(Linux系统)这样的IO多路复用技术在事件循环中不断处理客户端情况。
网络模型
系统资源由操作系统内核进行管理。内核空间可以执行特权命令(Ring0),调用一切系统资源。用户空间只能执行受限的命令(Ring3),而且不能直接调用系统资源,必须通过内核提供的接口来访问。为避免用户程序造成操作系统内核程序崩溃,内核线程和用户程序两者内存空间是隔离的。
整体流程:用户程序调用操作系统内核相关接口,操作系统内核线程调用驱动程序相关接口,驱动程序控制设备。


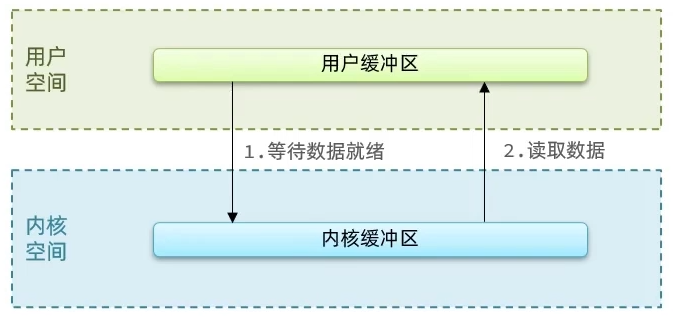
用户程序从设备读取数据:
- 转为内核态,内核线程从设备读取数据到内核缓冲区
- 转为用户态,用户程序从内核缓冲区读取到用户程序输入缓冲区
用户程序向设备写入数据:
- 转为用户态,用户程序向内核缓冲区写入数据
- 转为内核态,内核线程从内核缓冲区写入数据到设备
以用户程序从设备读取数据为例:
应用程序想要去读取数据,他是无法直接去读取磁盘数据的,他需要先到内核里边去等待内核操作硬件拿到数据,这个过程就是1,是需要等待的,等到内核从磁盘上把数据加载出来之后,再把这个数据写给用户的缓存区,这个过程是2,如果是阻塞IO,那么整个过程中,用户从发起读请求开始,一直到读取到数据,都是一个阻塞状态。

简化一下就是:
在《UNIX网络编程》一书中,总结归纳了5种IO模型:
- 阻塞IO(Blocking IO)
- 非阻塞IO(Nonblocking IO)
- IO多路复用(IO Multiplexing)
- 信号驱动IO(Signal Driven IO)
- 异步IO(Asynchronous IO)
Redis采用IO多路复用。
Redis IO模型
ae.c
ae.h
ae_select.c
ae_epoll.c
ae_kqueue.c
ae_evport.c
当我们的客户端想要去连接我们服务器,会去先到IO多路复用模型去进行排队,会有一个连接应答处理器,他会去接受读请求,然后又把读请求注册到具体模型中去,此时这些建立起来的连接,如果是客户端请求处理器去进行执行命令时,他会去把数据读取出来,然后把数据放入到client中, clinet去解析当前的命令转化为redis认识的命令,接下来就开始处理这些命令,从redis中的command中找到这些命令,然后就真正的去操作对应的数据了,当数据操作完成后,会去找到命令回复处理器,再由他将数据写出。

Redis 6.0版本中引入了多线程,目的是为了提高IO读写效率。因此在解析客户端命令、写响应结果时采用了多线程。核心的命令执行、IO多路复用模块依然是由主线程执行。

一定要给锁设置一个时间,否则服务宕机锁就没法自动释放了,时间还要尽量短一些,最好使用续期操作
- select
- poll
- epoll
其中select和pool相当于是当被监听的数据准备好之后,他会把你监听的FD整个数据都发给你,你需要到整个FD中去找,哪些是处理好了的,需要通过遍历的方式,所以性能也并不是那么好
而epoll,则相当于内核准备好了之后,他会把准备好的数据,直接发给你,咱们就省去了遍历的动作。
3.x及以前是纯粹单线程模型
4.x开始引入多线程。此时多线程负责持久化和异步删除。
正常情况下使用 del 指令可以很快的删除数据,而当被删除的 key 是一个非常大的对象时,例如时包含了成千上万个元素的 hash 集合时,那么 del 指令就会造成 Redis 主线程卡顿。
这就是redis3.x单线程时代最经典的故障,大key删除的头疼问题,
由于redis是单线程的,del bigKey …..
这个操作会阻塞redis主线程不少时间,于是乎,4.0引入了unlink删除
6.x开始更多采用了多线程,使用多线程在网络IO部分,但主进程执行命令依然是串行的。