不支持编码回退,编码转换不可逆
主要是数据增删频繁时,数据向压缩编码转换非常消耗CPU,得不偿失
object encoding key
debug object v
查看编码
https://redis.io/docs/latest/commands/?group=generic&name=object
底层数据结构
基本数据结构
SDS
本质是一个字符数组。
结构

一个包含字符串“name”的sds结构如下:

操作
存储上限为 512M
SDS 支持动态扩容:
- 字符串 a 要拼接上字符串 b,且字符串 a 剩余空间不足直接拼接 b。
- 若两个字符串占用小于 1M,则 a 扩容后空间为 a与b字符串长度之和的两倍 + 1。
- 若两个字符串占用大于 1M,则 a 扩容后空间为 a与b字符串长度之和 + 1M + 1。
二进制安全字符串
C 语言中,字符串可以用一个 \0 结尾的 char 数组来表示。hello world在 C 语言中就可以表示为“hello world\0”。若字符串二进制表示中本身就包含\0字符,就会导致字符串被提前断开。
Redis 中字符串要处理 Redis 通信过程中的字符串,故Redis 中的 string 需要保证二进制安全。
#include <stdio.h>
#include <string.h>
int binary_safe_strcmp(const char *str1, const char *str2, size_t len1, size_t len2);
int main() {
char normal_str[] = "Hello";
char unsafe_str[] = "Hello\0World";
printf("strlen(normal_str) returns %zu\n", strlen(normal_str));
printf("strlen(unsafe_str) returns %zu\n", strlen(unsafe_str));
// 静态分配的数组,使用 sizeof 分析其占用空间
printf("sizeof(normal_str) returns %zu\n", sizeof(normal_str));
printf("sizeof(unsafe_str) returns %zu\n", sizeof(unsafe_str));
// 返回0, 由于是非二进制安全,误判为相等
printf("strcmp(normal_str, unsafe_str) returns %d\n", strcmp(normal_str, unsafe_str));
// 二进制安全字符串比较,必须传入字符串长度,由于此次两个字符串均为静态分配,
// 可以使用 sizeof 获取长度,若使用动态内容分配,则需要额外使用变量记录分配时指定的长度
// SDS 中是由 len 字段记录字符串长度
printf("binary_safe_strcmp(normal_str, unsafe_str) returns %d\n",
binary_safe_strcmp(normal_str, unsafe_str, sizeof(normal_str), sizeof(unsafe_str)));
return 0;
}
int binary_safe_strcmp(const char *str1, const char *str2, size_t len1, size_t len2) {
// 如果长度不同,直接返回不相等
if (len1 != len2) {
return 1;
}
// 如果长度相同,使用memcmp比较内容
return memcmp(str1, str2, len1);
}
IntSet
本质是一个有序整数数组
结构
- encoding 指明整数数组中每个元素占用字节数
- lenght 指明元素个数
- contents 中存储集合数据


操作
- inset 由整数数组 contents 保存集合数据,数据从小到大有序排序,元素保证唯一。
- intset 查找元素采用二分查找算法。
- 自适应编码,若 intset 中存储的数据均为 2 字节整数,此时插入一个 8 字节整数,此时 intset 编码方式升级为 8 字节,所有数据均转为 8 字节数据。
若有一个intset,元素为{5,10,20},采用的编码是INTSET_ENC_INT16,则每个整数占2字节,向其中添加一个数字:50000,这个数字超出了int16_t的范围,intset会自动升级编码方式到合适的大小。
- 升级编码为INTSET_ENC_INT32, 每个整数占4字节,并按照新的编码方式及元素个数扩容数组
- 倒序依次将数组中的元素拷贝到扩容后的正确位置
- 将待添加的元素放入数组末尾
- 最后,将inset的encoding属性改为INTSET_ENC_INT32,将length属性改为4





添加元素
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
uint8_t valenc = _intsetValueEncoding(value);// 获取当前值编码
uint32_t pos; // 要插入的位置
if (success) *success = 1;
// 判断编码是不是超过了当前intset的编码
if (valenc > intrev32ifbe(is->encoding)) {
// 超出编码,需要升级
return intsetUpgradeAndAdd(is,value);
} else {
// 在当前intset中查找值与value一样的元素的角标pos
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0; //如果找到了,则无需插入,直接结束并返回失败
return is;
}
// 数组扩容
is = intsetResize(is,intrev32ifbe(is->length)+1);
// 移动数组中pos之后的元素到pos+1,给新元素腾出空间
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
// 插入新元素
_intsetSet(is,pos,value);
// 重置元素长度
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
编码升级
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
// 获取当前intset编码
uint8_t curenc = intrev32ifbe(is->encoding);
// 获取新编码
uint8_t newenc = _intsetValueEncoding(value);
// 获取元素个数
int length = intrev32ifbe(is->length);
// 判断新元素是大于0还是小于0 ,小于0插入队首、大于0插入队尾
int prepend = value < 0 ? 1 : 0;
// 重置编码为新编码
is->encoding = intrev32ifbe(newenc);
// 重置数组大小
is = intsetResize(is,intrev32ifbe(is->length)+1);
// 倒序遍历,逐个搬运元素到新的位置,_intsetGetEncoded按照旧编码方式查找旧元素
while(length--) // _intsetSet按照新编码方式插入新元素
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));
/* 插入新元素,prepend决定是队首还是队尾*/
if (prepend)
_intsetSet(is,0,value);
else
_intsetSet(is,intrev32ifbe(is->length),value);
// 修改数组长度
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
Dict
Redis 中映射关系由 dict 实现,dict 持有 dictht,dictht 持有 dictEntry 二维数组,dictEntry 存储键值对。
结构
typedef struct dict {
dictType *type; // dict类型,内置不同的hash函数
void *privdata; // 私有数据,在做特殊hash运算时用
dictht ht[2]; // 一个Dict包含两个哈希表,其中一个是当前数据,另一个一般是空,rehash时使用
long rehashidx; // rehash的进度,-1表示未进行
int16_t pauserehash; // rehash是否暂停,1则暂停,0则继续
} dict;
typedef struct dictht {
// entry数组
// 数组中保存的是指向entry的指针
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小的掩码,总等于size - 1
unsigned long sizemask;
// entry个数
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key; // 键
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; // 值
// 下一个Entry的指针
struct dictEntry *next;
} dictEntry;
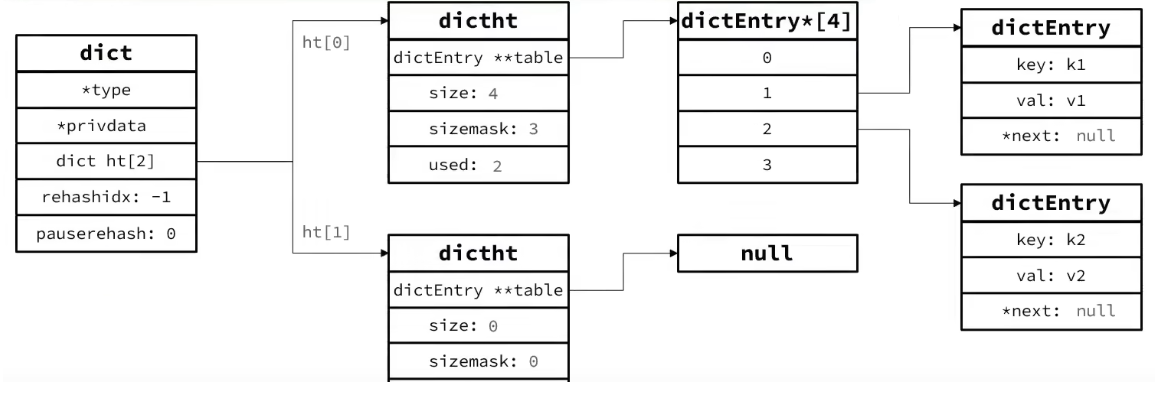

添加元素时自动扩容
Dict中的HashTable就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低。
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size) ,满足以下两种情况时会触发哈希表扩容:
- 哈希表的 LoadFactor >= 1,并且服务器没有执行 BGSAVE 或者 BGREWRITEAOF 等后台进程;
- 哈希表的 LoadFactor > 5 ;
static int _dictExpandIfNeeded(dict *d){
// 如果正在rehash,则返回ok
if (dictIsRehashing(d)) return DICT_OK;
// 如果哈希表为空,则初始化哈希表为默认大小:4
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
// 当负载因子(used/size)达到1以上,并且当前没有进行bgrewrite等子进程操作
// 或者负载因子超过5,则进行 dictExpand ,也就是扩容
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio){
// 扩容大小为used + 1,底层会对扩容大小做判断,实际上找的是第一个大于等于 used+1 的 2^n
return dictExpand(d, d->ht[0].used + 1);
}
return DICT_OK;
}
删除元素时自动缩容
Dict除了扩容以外,每次删除元素时,也会对负载因子做检查,当LoadFactor < 0.1 时,会做哈希表收缩:
自动扩缩容时 rehash
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这个过程称为rehash。基本思路是这样的:
- 计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^n
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n (不得小于4)
- 按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
- 设置dict.rehashidx = 0,标示开始rehash
- 将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1]
- 将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
Dict的rehash并不是一次性完成的。若Dict中包含数百万的entry,要在一次rehash完成,极有可能导致主线程阻塞。因此Dict的rehash是分多次、渐进式的完成,因此称为渐进式rehash。主要流程如下:
- 计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^n
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n (不得小于4)
- 按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
- 设置dict.rehashidx = 0,标示开始rehash
- 每次执行新增、查询、修改、删除操作时,都检查一下dict.rehashidx是否大于-1,如果是则将dict.ht[0].table[rehashidx]的entry链表rehash到dict.ht[1],并且将rehashidx++。直至dict.ht[0]的所有数据都rehash到dict.ht[1]
- 将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
- 将rehashidx赋值为-1,代表rehash结束
- 在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空
LinkedList
双向链表,可以从双端访问,内存占用较高,内存碎片较多
ZipList
压缩列表,可以从双端访问,内存占用低,存储上限低,内存连续
ZipList 是一种特殊的“双端链表” ,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作, 并且该操作的时间复杂度为 O(1)。
但是内存连续,因为一个指针需要8个字节(因为是64位系统),双向链表每个结点需要两个指针就是16个字节,ZipList通过编码写明结点数据类型、当前结点长度、前一结点长度,总消耗不超过10byte,所以一定程度上对数据进行了压缩,压缩的代价是内存连续了
结构

| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4 字节 | 记录整个压缩列表占用的内存字节数 |
| zltail | uint32_t | 4 字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节,通过这个偏移量,可以确定表尾节点的地址。 |
| zllen | uint16_t | 2 字节 | 记录了压缩列表包含的节点数量。 最大值为UINT16_MAX (65534),如果超过这个值,此处会记录为65535,但节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entry | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
| zlend | uint8_t | 1 字节 | 特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |
ZipListEntry
ZipList 中的 Entry 并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用16个字节,浪费内存。而是采用了下面的结构:

previous_entry_length:前一节点的长度,占1个或5个字节。
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值,第一个字节为 0xfe,后四个字节才是真实长度数据
encoding:编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节
contents:负责保存节点的数据,可以是字符串或整数
ZipList中所有存储长度的数值均采用小端字节序,即低位字节在前,高位字节在后。例如:数值0x1234,采用小端字节序后实际存储值为:0x3412
连锁更新问题
ZipList的每个Entry都包含previous_entry_length来记录上一个节点的大小,长度是1个或5个字节:
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
若有N个连续的、长度为250~253字节之间的entry,因此entry的previous_entry_length属性用1个字节即可表示。


此时左侧插入一个 254字节的entry,后续若干 entry 必须全部更新。


ZipList这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新(Cascade Update)。新增、删除都可能导致连锁更新的发生。
QuickList
LinkedList + ZipList,可以从双端访问,内存占用较低,包含多个ZipList,存储上限高
- 是一个节点为ZipList的双端链表
- 节点采用ZipList,解决了传统链表的内存占用问题
- 控制了ZipList大小,解决连续内存空间申请效率问题
QuickList 的出现用于解决 ZipList 的弊端:
- ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。为了缓解这个问题,必须限制ZipList的长度和entry大小。
- 但是我们要存储大量数据,超出了ZipList最佳的上限。可以创建多个ZipList来分片存储数据。
- 数据拆分后比较分散,不方便管理和查找。Redis在3.2版本引入了新的数据结构QuickList,它是一个双端链表,只不过链表中的每个节点都是一个ZipList。
结构
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: 0 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor.
* 'bookmarks are an optional feature that is used by realloc this struct,
* so that they don't consume memory when not used. */
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all listpacks */
unsigned long len; /* number of quicklistNodes */
signed int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
/* quicklistNode is a 32 byte struct describing a listpack for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max lp bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, PLAIN=1 (a single item as char array), PACKED=2 (listpack with multiple items).
* recompress: 1 bit, bool, true if node is temporary decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *entry;
size_t sz; /* entry size in bytes */
unsigned int count : 16; /* count of items in listpack */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* PLAIN==1 or PACKED==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
/* Bookmarks are padded with realloc at the end of of the quicklist struct.
* They should only be used for very big lists if thousands of nodes were the
* excess memory usage is negligible, and there's a real need to iterate on them
* in portions.
* When not used, they don't add any memory overhead, but when used and then
* deleted, some overhead remains (to avoid resonance).
* The number of bookmarks used should be kept to minimum since it also adds
* overhead on node deletion (searching for a bookmark to update). */
typedef struct quicklistBookmark {
quicklistNode *node;
char *name;
} quicklistBookmark;
typedef struct quicklist {
// 头节点指针
quicklistNode *head;
// 尾节点指针
quicklistNode *tail;
// 所有ziplist的entry的数量
unsigned long count;
// ziplists总数量
unsigned long len;
// ziplist的entry上限,默认值 -2
int fill : QL_FILL_BITS;
// 首尾不压缩的节点数量
unsigned int compress : QL_COMP_BITS;
// 内存重分配时的书签数量及数组,一般用不到
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistNode {
// 前一个节点指针
struct quicklistNode *prev;
// 下一个节点指针
struct quicklistNode *next;
// 当前节点的ZipList指针
unsigned char *zl;
// 当前节点的ZipList的字节大小
unsigned int sz;
// 当前节点的ZipList的entry个数
unsigned int count : 16;
// 编码方式:1,ZipList; 2,lzf压缩模式
unsigned int encoding : 2;
// 数据容器类型(预留):1,其它;2,ZipList
unsigned int container : 2;
// 是否被解压缩。1:则说明被解压了,将来要重新压缩
unsigned int recompress : 1;
unsigned int attempted_compress : 1; //测试用
unsigned int extra : 10; /*预留字段*/
} quicklistNode;

为了避免QuickList中的每个ZipList中entry过多,Redis提供了一个配置项:list-max-ziplist-size来限制。
- 如果值为正,则代表ZipList的允许的entry个数的最大值
- 如果值为负,则代表ZipList的最大内存大小,分5种情况:
- -1:每个ZipList的内存占用不能超过4kb
- -2:每个ZipList的内存占用不能超过8kb
- -3:每个ZipList的内存占用不能超过16kb
- -4:每个ZipList的内存占用不能超过32kb
- -5:每个ZipList的内存占用不能超过64kb
其默认值为 -2:

除了控制ZipList的大小,QuickList还可以对节点的ZipList做压缩。通过配置项list-compress-depth来控制。因为链表一般都是从首尾访问较多,所以首尾是不压缩的。这个参数是控制首尾不压缩的节点个数:
0:特殊值,代表不压缩
1:标示QuickList的首尾各有1个节点不压缩,中间节点压缩
2:标示QuickList的首尾各有2个节点不压缩,中间节点压缩
以此类推
默认值:

SkipList
- 跳跃表是一个双向链表,每个节点都包含score和ele值
- 节点按照score值排序,score值一样则按照ele字典排序
- 使用多层指针做索引
- 每个节点都可以包含多层指针,层数是1到32之间的随机数
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率与红黑树基本一致,实现却更简单
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同
// t_zset.c
typedef struct zskiplist {
// 头尾节点指针
struct zskiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 最大的索引层级,默认是1
int level;
} zskiplist;
// t_zset.c
typedef struct zskiplistNode {
sds ele; // 节点存储的值
double score;// 节点分数,排序、查找用
struct zskiplistNode *backward; // 前一个节点指针
struct zskiplistLevel {
struct zskiplistNode *forward; // 下一个节点指针
unsigned long span; // 索引跨度
} level[]; // 多级索引数组
} zskiplistNode;

Redis 数据类型实现
统一抽象 redisObject
Redis 中数据被统一抽象为 redisObject,redisObject 存储某一类型数据,某类型数据根据当前数据的具体情况采用某编码方式,某编码方式采用某底层数据结构实现。具体实现遵循数据类型->编码方式->底层数据结构。
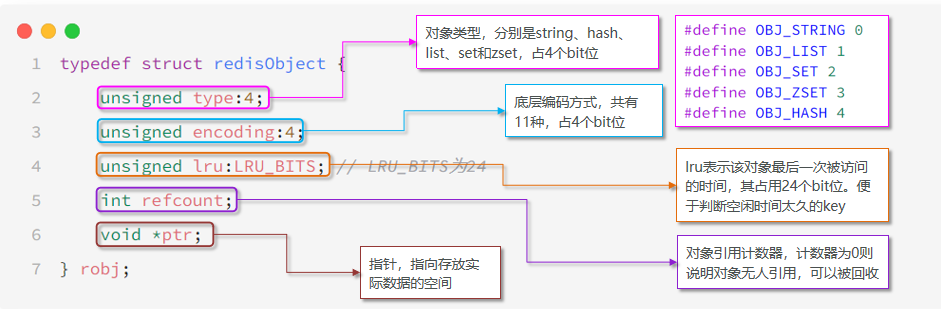
- type:指明当前 redisObject 存储数据的类型
- encoding:指明当前 redisObject 存储数据的编码方式
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* No longer used: old hash encoding. */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* No longer used: old list/hash/zset encoding. */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of listpacks */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
#define OBJ_ENCODING_LISTPACK 11 /* Encoded as a listpack */
#define LRU_BITS 24
typedef struct redisObject {
unsigned type:4; //4bit
unsigned encoding:4; //4bit
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
//24bit
int refcount; //4byte
void *ptr; //8byte
} robj;
Redis的编码方式
Redis中会根据存储的数据类型不同,选择不同的编码方式,共包含11种不同类型:
| 编号 | 编码方式 | 说明 |
|---|---|---|
| 0 | OBJ_ENCODING_RAW | raw编码动态字符串 |
| 1 | OBJ_ENCODING_INT | long类型的整数的字符串 |
| 2 | OBJ_ENCODING_HT | hash表(字典dict) |
| 3 | OBJ_ENCODING_ZIPMAP | 已废弃 |
| 4 | OBJ_ENCODING_LINKEDLIST | 双端链表 |
| 5 | OBJ_ENCODING_ZIPLIST | 压缩列表 |
| 6 | OBJ_ENCODING_INTSET | 整数集合 |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表 |
| 8 | OBJ_ENCODING_EMBSTR | embstr的动态字符串 |
| 9 | OBJ_ENCODING_QUICKLIST | 快速列表 |
| 10 | OBJ_ENCODING_STREAM | Stream流 |
五种数据结构
Redis中会根据存储的数据类型不同,选择不同的编码方式。每种数据类型的使用的编码方式如下:
| 数据类型 | 编码方式 |
|---|---|
| OBJ_STRING | int、embstr、raw |
| OBJ_LIST | LinkedList和ZipList(3.2以前) -> QuickList(3.2以后) |
| OBJ_SET | intset、HT |
| OBJ_ZSET | ZipList、HT、SkipList |
| OBJ_HASH | ZipList、HT |

string
底层数据类型包含int、embstr、raw,embstr在小于等于44字节时使用连续内存,占用更小
OBJ_ENCODING_INT

int 编码方式直接使用 long 类型存储数据。
OBJ_ENCODING_EMBSTR

embstr 编码方式使用 SDS 存储数据,head 与 SDS 内存连续,一次内存分配调用。
OBJ_ENCODING_RAW

embstr 编码方式使用 SDS 存储数据,head 与 SDS 内存不连续,两次内存分配调用。
编码选择
- 如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了。
- 存储的SDS长度小于44字节,则会采用EMBSTR编码,此时object head与SDS是一段连续空间。申请内存时只需要调用一次内存分配函数,效率更高。
- 其基本编码方式是RAW,基于简单动态字符串(SDS)实现,存储上限为512mb。
编码转换
自增操作
- 若为 OBJ_ENCODING_INT 编码,直接进行自增操作
- 若为 OBJ_ENCODING_EMBSTR 或 OBJ_ENCODING_RAW 编码,尝试将 SDS 转为 long 再进行操作
位操作,setbit
- 若为 OBJ_ENCODING_EMBSTR 或 OBJ_ENCODING_RAW 编码,则直接进行操作
- 若为 OBJ_ENCODING_INT,尝试将 long 转为 SDS 再进行操作。
list
OBJ_ENCODING_QUICKLIST

- LinkedList :普通链表,可以从双端访问,内存占用较高,内存碎片较多
- ZipList :压缩列表,可以从双端访问,内存占用低,存储上限低
- QuickList:LinkedList + ZipList,可以从双端访问,内存占用较低,包含多个ZipList,存储上限高
Redis的List结构类似一个双端链表,可以从首、尾操作列表中的元素:
在3.2版本之前,Redis采用ZipList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。
在3.2版本之后,Redis统一采用QuickList来实现List:
void pushGenericCommand(client *c, int where, int xx) {
int j;
// 尝试找到KEY对应的list
robj *lobj = lookupKeyWrite(c->db, c->argv[1]);
// 检查类型是否正确
if (checkType(c,lobj,OBJ_LIST)) return;
// 检查是否为空
if (!lobj) {
if (xx) {
addReply(c, shared.czero);
return;
}
// 为空,则创建新的QuickList
lobj = createQuicklistObject();
quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,
server.list_compress_depth);
dbAdd(c->db,c->argv[1],lobj);
}
// 略 ...
}
robj *createQuicklistObject(void) {
// 申请内存并初始化QuickList
quicklist *l = quicklistCreate();
// 创建RedisObject,type为OBJ_LIST
// ptr指向 QuickList
robj *o = createObject(OBJ_LIST,l);
// 设置编码为 QuickList
o->encoding = OBJ_ENCODING_QUICKLIST;
return o;
}
set
Set是Redis中的集合,不一定确保元素有序,可以满足元素唯一、查询效率要求极高。
- 不保证有序性
- 保证元素唯一
- 求交集、并集、差集
OBJ_ENCODING_INTSET
使用 IntSet 存储数据

OBJ_ENCODING_HT
使用 Dict 存储数据

编码选择
为了查询效率和唯一性,set采用HT编码(Dict)。Dict中的key用来存储元素,value统一为null。
当存储的所有数据都是整数,并且元素数量不超过set-max-intset-entries时,Set会采用IntSet编码,以节省内存。set-max-intset-entries的默认值是512

robj *setTypeCreate(sds value) {
// 判断value是否是数值类型 long long
if (isSdsRepresentableAsLongLong(value,NULL) == C_OK)
// 如果是数值类型,则采用IntSet编码
return createIntsetObject();
// 否则采用默认编码,也就是HT
return createSetObject();
}
robj *createIntsetObject(void) {
// 初始化INTSET并申请内存空间
intset *is = intsetNew();
// 创建RedisObject
robj *o = createObject(OBJ_SET,is);
// 指定编码为INTSET
o->encoding = OBJ_ENCODING_INTSET;
return o;
}
robj *createSetObject(void) {
// 初始化Dict类型,并申请内存
dict *d = dictCreate(&setDictType,NULL);
// 创建RedisObject
robj *o = createObject(OBJ_SET,d);
// 设置encoding为HT
o->encoding = OBJ_ENCODING_HT;
return o;
}
OBJ_ENCODING_SKIPLIST
hash
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
/* Keep small vars at end for optimal (minimal) struct padding */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */
};
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(dict *d, const void *key);
void *(*valDup)(dict *d, const void *obj);
int (*keyCompare)(dict *d, const void *key1, const void *key2);
void (*keyDestructor)(dict *d, void *key);
void (*valDestructor)(dict *d, void *obj);
int (*expandAllowed)(size_t moreMem, double usedRatio);
/* Allow a dictEntry to carry extra caller-defined metadata. The
* extra memory is initialized to 0 when a dictEntry is allocated. */
size_t (*dictEntryMetadataBytes)(dict *d);
} dictType;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /* Next entry in the same hash bucket. */
void *metadata[]; /* An arbitrary number of bytes (starting at a
* pointer-aligned address) of size as returned
* by dictType's dictEntryMetadataBytes(). */
} dictEntry;
OBJ_ENCODING_ZIPLIST

OBJ_ENCODING_HT

编码适用
Hash结构默认采用ZipList编码,用以节省内存。 ZipList中相邻的两个entry 分别保存field和value
当数据量较大时,Hash结构会转为HT编码,也就是Dict,触发条件有两个:
ZipList中的元素数量超过了hash-max-ziplist-entries(默认512)
ZipList中的任意entry大小超过了hash-max-ziplist-value(默认64字节)

void hsetCommand(client *c) {// hset user1 name Jack age 21
int i, created = 0;
robj *o; // 略 ...
// 判断hash的key是否存在,不存在则创建一个新的,默认采用ZipList编码
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
// 判断是否需要把ZipList转为Dict
hashTypeTryConversion(o,c->argv,2,c->argc-1);
// 循环遍历每一对field和value,并执行hset命令
for (i = 2; i < c->argc; i += 2)
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
// 略 ...
}
robj *hashTypeLookupWriteOrCreate(client *c, robj *key) {
// 查找key
robj *o = lookupKeyWrite(c->db,key);
if (checkType(c,o,OBJ_HASH)) return NULL;
// 不存在,则创建新的
if (o == NULL) {
o = createHashObject();
dbAdd(c->db,key,o);
}
return o;
}
robj *createHashObject(void) {
// 默认采用ZipList编码,申请ZipList内存空间
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_HASH, zl);
// 设置编码
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {
int i;
size_t sum = 0;
// 本来就不是ZipList编码,什么都不用做了
if (o->encoding != OBJ_ENCODING_ZIPLIST) return;
// 依次遍历命令中的field、value参数
for (i = start; i <= end; i++) {
if (!sdsEncodedObject(argv[i]))
continue;
size_t len = sdslen(argv[i]->ptr);
// 如果field或value超过hash_max_ziplist_value,则转为HT
if (len > server.hash_max_ziplist_value) {
hashTypeConvert(o, OBJ_ENCODING_HT);
return;
}
sum += len;
}// ziplist大小超过1G,也转为HT
if (!ziplistSafeToAdd(o->ptr, sum))
hashTypeConvert(o, OBJ_ENCODING_HT);
}
int hashTypeSet(robj *o, sds field, sds value, int flags) {
int update = 0;
// 判断是否为ZipList编码
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl, *fptr, *vptr;
zl = o->ptr;
// 查询head指针
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) { // head不为空,说明ZipList不为空,开始查找key
fptr = ziplistFind(zl, fptr, (unsigned char*)field, sdslen(field), 1);
if (fptr != NULL) {// 判断是否存在,如果已经存在则更新
update = 1;
zl = ziplistReplace(zl, vptr, (unsigned char*)value,
sdslen(value));
}
}
// 不存在,则直接push
if (!update) { // 依次push新的field和value到ZipList的尾部
zl = ziplistPush(zl, (unsigned char*)field, sdslen(field),
ZIPLIST_TAIL);
zl = ziplistPush(zl, (unsigned char*)value, sdslen(value),
ZIPLIST_TAIL);
}
o->ptr = zl;
/* 插入了新元素,检查list长度是否超出,超出则转为HT */
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
} else if (o->encoding == OBJ_ENCODING_HT) {
// HT编码,直接插入或覆盖
} else {
serverPanic("Unknown hash encoding");
}
return update;
}
负载因子
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (DICTHT_SIZE(d->ht_size_exp[0]) == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (//哈希因子大于1
d->ht_used[0] >= DICTHT_SIZE(d->ht_size_exp[0]) &&
//可以resize或者哈希因子大于强制resize阈值
(dict_can_resize || d->ht_used[0]/ DICTHT_SIZE(d->ht_size_exp[0]) > dict_force_resize_ratio) &&
//dictType允许扩容
dictTypeExpandAllowed(d)
) {
return dictExpand(d, d->ht_used[0] + 1);
}
return DICT_OK;
}
/* Resize the table to the minimal size that contains all the elements,
* but with the invariant of a USED/BUCKETS ratio near to <= 1 */
//第一个大于等于2^n
int dictResize(dict *d)
{
unsigned long minimal;
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht_used[0];
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal);
}
/* Expand or create the hash table,
* when malloc_failed is non-NULL, it'll avoid panic if malloc fails (in which case it'll be set to 1).
* Returns DICT_OK if expand was performed, and DICT_ERR if skipped. */
int _dictExpand(dict *d, unsigned long size, int* malloc_failed)
{
if (malloc_failed) *malloc_failed = 0;
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht_used[0] > size)
return DICT_ERR;
/* the new hash table */
dictEntry **new_ht_table;
unsigned long new_ht_used;
signed char new_ht_size_exp = _dictNextExp(size);
/* Detect overflows */
size_t newsize = 1ul<<new_ht_size_exp;
if (newsize < size || newsize * sizeof(dictEntry*) < newsize)
return DICT_ERR;
/* Rehashing to the same table size is not useful. */
if (new_ht_size_exp == d->ht_size_exp[0]) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
if (malloc_failed) {
new_ht_table = ztrycalloc(newsize*sizeof(dictEntry*));
*malloc_failed = new_ht_table == NULL;
if (*malloc_failed)
return DICT_ERR;
} else
new_ht_table = zcalloc(newsize*sizeof(dictEntry*));
new_ht_used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht_table[0] == NULL) {
d->ht_size_exp[0] = new_ht_size_exp;
d->ht_used[0] = new_ht_used;
d->ht_table[0] = new_ht_table;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht_size_exp[1] = new_ht_size_exp;
d->ht_used[1] = new_ht_used;
d->ht_table[1] = new_ht_table;
d->rehashidx = 0;
return DICT_OK;
}
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht_used[0] != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(DICTHT_SIZE(d->ht_size_exp[0]) > (unsigned long)d->rehashidx);
while(d->ht_table[0][d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht_table[0][d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & DICTHT_SIZE_MASK(d->ht_size_exp[1]);
de->next = d->ht_table[1][h];
d->ht_table[1][h] = de;
d->ht_used[0]--;
d->ht_used[1]++;
de = nextde;
}
d->ht_table[0][d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht_used[0] == 0) {
zfree(d->ht_table[0]);
/* Copy the new ht onto the old one */
d->ht_table[0] = d->ht_table[1];
d->ht_used[0] = d->ht_used[1];
d->ht_size_exp[0] = d->ht_size_exp[1];
_dictReset(d, 1);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
ZSET
ZSet也就是SortedSet,其中每一个元素都需要指定一个score值和member值:
- 可以根据score值排序后
- member必须唯一
- 可以根据member查询分数
两份数据,一份Dict、一份SkipList
因此,zset底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求。之前学习的哪种编码结构可以满足?
- SkipList:可以排序,并且可以同时存储score和ele值(member)
- HT(Dict):可以键值存储,并且可以根据key找value
// zset结构
typedef struct zset {
// Dict指针
dict *dict;
// SkipList指针
zskiplist *zsl;
} zset;
robj *createZsetObject(void) {
zset *zs = zmalloc(sizeof(*zs));
robj *o;
// 创建Dict
zs->dict = dictCreate(&zsetDictType,NULL);
// 创建SkipList
zs->zsl = zslCreate();
o = createObject(OBJ_ZSET,zs);
o->encoding = OBJ_ENCODING_SKIPLIST;
return o;
}
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
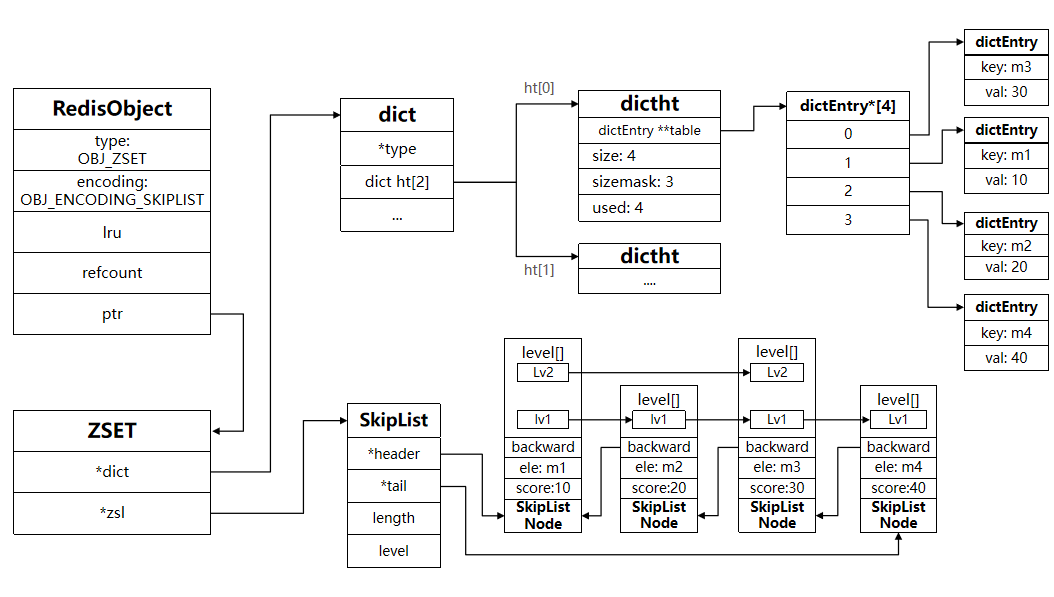
当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此zset还会采用ZipList结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于zset_max_ziplist_entries,默认值128
- 每个元素都小于zset_max_ziplist_value字节,默认值64
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
- ZipList是连续内存,因此score和element是紧挨在一起的两个entry, element在前,score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排列
// zadd添加元素时,先根据key找到zset,不存在则创建新的zset
zobj = lookupKeyWrite(c->db,key);
if (checkType(c,zobj,OBJ_ZSET)) goto cleanup;
// 判断是否存在
if (zobj == NULL) { // zset不存在
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr))
{ // zset_max_ziplist_entries设置为0就是禁用了ZipList,
// 或者value大小超过了zset_max_ziplist_value,采用HT + SkipList
zobj = createZsetObject();
} else { // 否则,采用 ZipList
zobj = createZsetZiplistObject();
}
dbAdd(c->db,key,zobj);
}
// ....
zsetAdd(zobj, score, ele, flags, &retflags, &newscore);
robj *createZsetObject(void) {
// 申请内存
zset *zs = zmalloc(sizeof(*zs));
robj *o;
// 创建Dict
zs->dict = dictCreate(&zsetDictType,NULL);
// 创建SkipList
zs->zsl = zslCreate();
o = createObject(OBJ_ZSET,zs);
o->encoding = OBJ_ENCODING_SKIPLIST;
return o;
}
robj *createZsetZiplistObject(void) {
// 创建ZipList
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_ZSET,zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}
int zsetAdd(robj *zobj, double score, sds ele, int in_flags, int *out_flags, double *newscore) {
/* 判断编码方式*/
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {// 是ZipList编码
unsigned char *eptr;
// 判断当前元素是否已经存在,已经存在则更新score即可
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
//...略
return 1;
} else if (!xx) {
// 元素不存在,需要新增,则判断ziplist长度有没有超、元素的大小有没有超
if (zzlLength(zobj->ptr)+1 > server.zset_max_ziplist_entries
|| sdslen(ele) > server.zset_max_ziplist_value
|| !ziplistSafeToAdd(zobj->ptr, sdslen(ele)))
{ // 如果超出,则需要转为SkipList编码
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
} else {
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
if (newscore) *newscore = score;
*out_flags |= ZADD_OUT_ADDED;
return 1;
}
} else {
*out_flags |= ZADD_OUT_NOP;
return 1;
}
}
// 本身就是SKIPLIST编码,无需转换
if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
// ...略
} else {
serverPanic("Unknown sorted set encoding");
}
return 0; /* Never reached. */
}
OBJ_ENCODING_ZIPLIST
OBJ_ENCODING_SKIPLIST
OBJ_ENCODING_HT
HyperLogLog
https://juejin.cn/post/6844903785744056333
HyperLogLog用于海量数据的基数统计。基于概率估计,有一定误差。
投硬币,根据概率,出现正面的概率为$\frac{1}{2}$:
- 当投的次数足够多时,出现正面和反面的比例越接近1:1
- 假设投k次硬币直到出现第一次正面算作一轮,那么根据概率
桶共计$2^{14}$个,每个桶占用6bit,共计$2^{10}812b=12kb$
bit_sequence_64 = hash(value)
64bit,前14位用于区分桶,后50位用于进行统计
50位中从低位到高位,0表示反面,1表示正面,r为第一次出现1的位数
r会被存储在对应桶中,$2^6>50$,可以存储所有情况
$$
DV_{LogLog}=constantm2^{avg(r)}
$$
$$
DV_{HyperLogLog}=constantm2^{avg(r)}
$$
http://content.research.neustar.biz/blog/hll.html
https://juejin.cn/post/6844903785744056333
二进制安全
通俗的讲,C语言中,用“0”表示字符串的结束,如果字符串中本身就有“0”字符,那么这个字符串就会被截断,即非二进制安全;若通过某种机制,保证读写字符串时不损害其内容,则是二进制安全。
C语言中非二进制安全
main(){
char ab[] = "Hello";
char ac[] = "Hello\0Hello";
/*返回0, 由于是非二进制安全,误判为相等 */
strcmp(ab, ac);
}
而redis除了要处理c语言字符串之外,还需要处理redis的服务器协议等等。所以,redis实现的sds(简单动态字符串),是二进制安全的。
Redis3.2之前
typedef char *sds;
struct sdshdr {
// buf 已占用长度
int len;
// buf 剩余可用长度
int free;
// 实际保存字符串数据的地方
char buf[];
};